 Open Archieven heeft nu een tweede crowdsourcingsproject: de woningkaarten van Nijmegen (1920-1946).
Open Archieven heeft nu een tweede crowdsourcingsproject: de woningkaarten van Nijmegen (1920-1946).
De door het Regionaal Archief Nijmegen aangeleverde data (bestaande uit 26.458 records) bevatte per woningkaart een link naar één scan. Het idee hierachter was dat de woningkaarten dubbelzijdig zijn en de achterkant vaak leeg was. Bij een steekproef bleek mij echter dat het ook vaak voorkwam dat er meerdere scans waren gekoppeld aan één woningkaart. Het meest extreme voorbeeld was de woningkaart van Westkanaaldijk 301 (Weesinrichting Neerbosch) waaraan maar liefst 290 scans aan gekoppeld waren. Via wat ‘scripting’ heb ik per woningkaart achterhaald welke scans eraan welke woningkaart waren gekoppeld. In onderstaande grafiek (met logaritmische y-as) kan worden afgelezen hoeveel woningkaarten een bepaald aantal gekoppelde scans heeft.
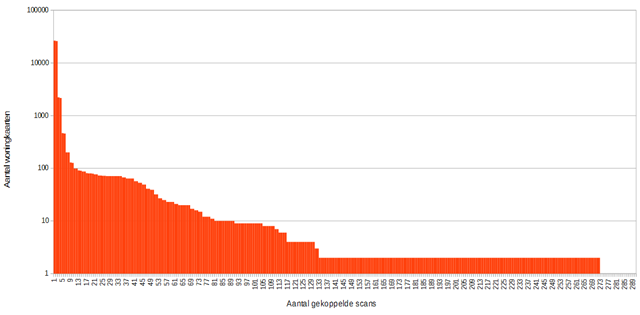
Als alleen de eerste scan van een woningkaart geïndexeerd zou worden (dus de eerste verticale balk in bovenstaande grafiek) zou een groot deel (35.950 scans) ongeïndexeerd blijven. Dit leek mij geen goed idee, vandaar dat alle scans zijn ingelezen in de indexeringstool van Open Archieven.
Scan bevat geen informatie
Toen alle 59.667 scans waren opgenomen kwam je bij het indexeren wel vaak een lege woningkaart tegen, te vaak… De indexeerder heeft de mogelijkheid om aan te geven dat de scan geen informatie bevat, maar dit voelt toch niet fijn als je wilt indexeren. Bij crowd-sourcing vraag je aan mensen om een relatief eenvoudige taak uit te voeren die voor de computer te lastig is. Een mens ziet eenvoudig of een kaart leeg is, maar een computer?

De uitdaging die werd opgepakt: bedenk (en maak) een algoritme die een scan van een ingevulde woningkaart kan onderscheiden van een scan van een lege woningkaart. De gekozen aanpak gaat ervan uit dat de woningkaarten een vaste structuur hebben. Er wordt uit de woningkaart een gedeelte gepakt die overeenkomt met ruwweg de 1e cel van het ‘formulier’ (hieronder weergegeven door de gele rechthoek). Het aantal kleuren van dit gedeelte wordt teruggebracht naar een zeer beperkt aantal kleuren. Hierna wordt er ‘geteld’ hoeveel zwarte pixels er in voorkomen. Wanneer dit aantal hoger is dan een bepaalde drempelwaarde, dan staat er tekst!
 Een visuele controle van de methode leerde dat het algoritme vrij goed werkte maar niet perfect is, of beter gezegd de uitgangspunten die ten grondslag liggen aan het algoritme zijn niet altijd waar. Een enkele keer begint de tekst in de 2e cel, soms is de kaart donker waardoor er meer zwart wordt ‘gezien’, soms is de structuur van de kaart net iets anders, enz.
Een visuele controle van de methode leerde dat het algoritme vrij goed werkte maar niet perfect is, of beter gezegd de uitgangspunten die ten grondslag liggen aan het algoritme zijn niet altijd waar. Een enkele keer begint de tekst in de 2e cel, soms is de kaart donker waardoor er meer zwart wordt ‘gezien’, soms is de structuur van de kaart net iets anders, enz.
Kwaliteit van indexeren
Om hoge kwaliteit indexen te krijgen wordt elke kaart minimaal 2 keer geïndexeerd. Als er twee maal hetzelfde is ingevoerd (door twee verschillende indexeerders) dan kan worden aangenomen dat de tekst goed is overgenomen (de kans dat twee personen dezelfde fout maken is erg klein). Komt de invoer niet overeen dan wordt de kaart voor een 3e keer ter indexering aangeboden. Is er hierna nog niet een set van 2 overeenstemmende invoersets dan kijkt een controleur er naar.
Omdat er niet volledig op het lege-kaart-detectie-algoritme kan worden vertrouwd worden de indexeerders hierbij ingeschakeld. Het algoritme zorgt voor de 1e invoer – ruim 4 duizend herkende lege kaarten – en de indexeerders voor de 2e invoer. Op deze manier krijgen indexeerders de helft minder lege kaarten te zien en wordt de uitkomst van het algoritme gecontroleerd door de indexeerder (doordat hij/zij aangeeft dat de scan geen informatie bevat).
Nu is het even afwachten totdat de indexeerders alle woonkaarten hebben geïndexeerd, dan wordt zichtbaar of het algoritme veel of weinig lege kaarten heeft gemist. Hoe dan ook is er dan weer een mooie index beschikbaar, die voor een ieder als open data beschikbaar is!
