Diegenen die de OpenAI’s ChatGPT tool gebruiken cq. aan het uit proberen zijn én een abonnement hebben kunnen gebruik maken van plug-ins van derden. Als dienstaanbieder is het natuurlijk interessant om te kijken of je voor jou dienst een plugin kunt realiseren zodat ChatGPT deze kan gebruiken. Als experiment heb ik Open Archieven gekoppeld.
Als je platform open is en gebruik maakt van standaarden dan is de realisatie van de plugin zeer eenvoudig. Open Archieven, biedt diverse API‘s. Deze zijn beschreven op basis van de Open API specificatie in een online YAML bestand. Een ai-plugin.json bestand op je domein bevat de configuratie van je plugin, waarin het meest belangrijke de url van de Open API url is. Dit JSON bestand moet onder die naam geplaatst worden in de .well-known directory op je website zodat je aan ChatGPT alleen het domeinnaam hoeft op te geven (hier dus www.openarch.nl) en je kunt aan de slag (nu nog als developer, ik heb de plugin nog niet aangeboden om in de plugin-store te komen).
Door de YAML beschrijving van je API ‘weet’ de AI wanneer het welke vraag moet stellen. Hieronder enkele voorbeelden met hier en daar wat observaties.
Bij de eerste vraag heeft ChatGPT op de achtergrond het volgende request gedaan: https://api.openarch.nl/1.1/records/getBirths.json?name=Wilhelmus%20Coret De gestuctureerde JSON resultaten zijn dus in mooi Nederlands (want ik stelde de vraag in het Nederlands) omzet mét links naar de akten. Onverwacht werden er ook afbeeldingen en titels getoond van de aktes. Hiervoor zorgt een andere door Open Archieven gehanteerde standaard: Open Graph.
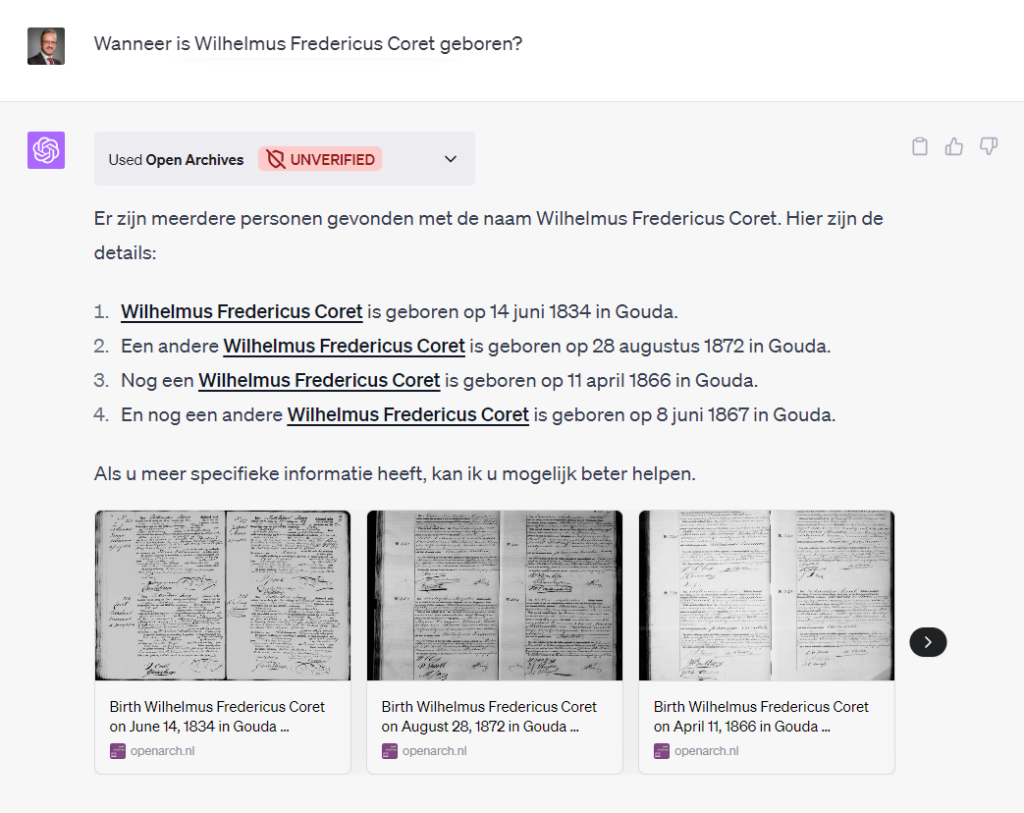
Het is een chat, dus je kunt doorvragen, bijvoorbeeld naar de bronnen. Alle akten uit de vorige vraag komen inderdaad van het Streekarchief Midden-Holland. Maar de uitleg over dit archief komt niet van de Open Archieven plugin, dat verzint ChatGPT er zelf aardig bij. Hetzelfde zie je gebeuren bij de vraag naar het brontype.

De weergave varieert, hieronder zijn de namen niet gelinkt maar bevat elke regel een “Link naar de akte”. Doordat ik in de prompt ook vroeg naar het archief, zie je dit netjes in het antwoord terug.
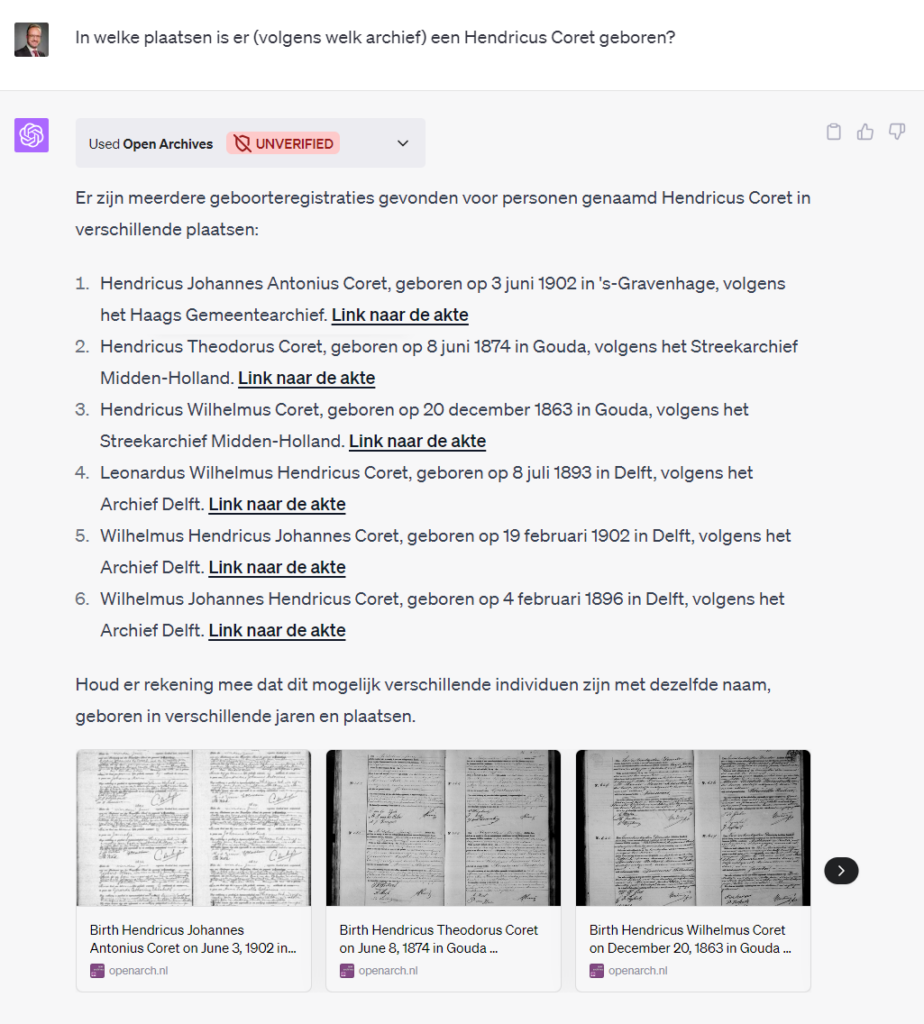
Bij Open Archieven (en dus ook via de API) kun je zoeken met wildcards. ChatGPT snapt dit en geeft aan de API “Hendr* Coret” mee via de name-parameter!
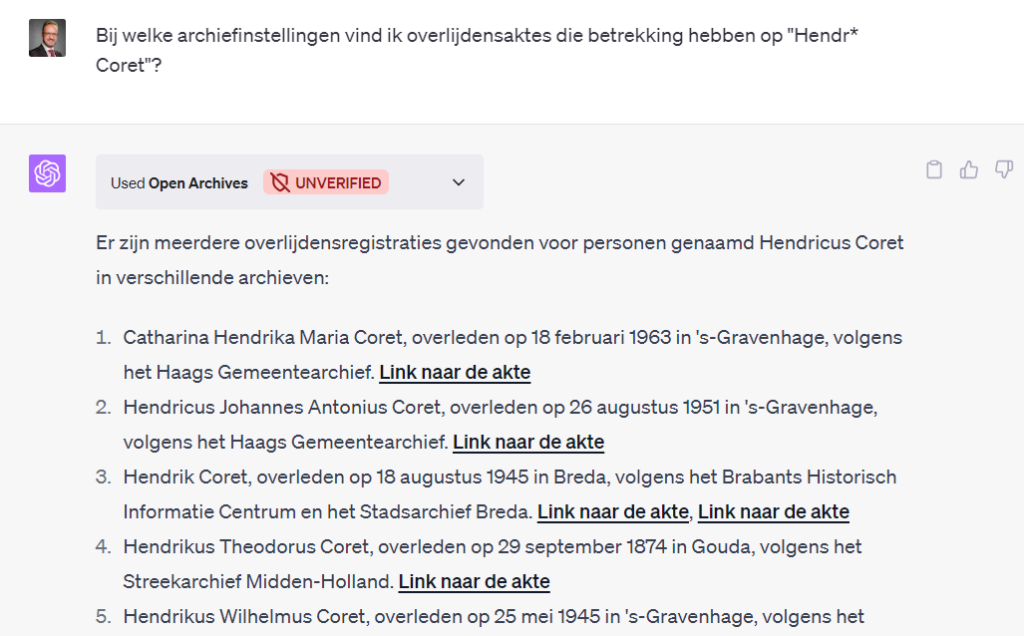
In de volgende vraag heeft ChatGPT goed gezien dat ik de getMarriages methode van de API wil aanroepen en dus twee namen als losse parameters (name1 en name2) meegegeven moeten worden in de API aanroep.
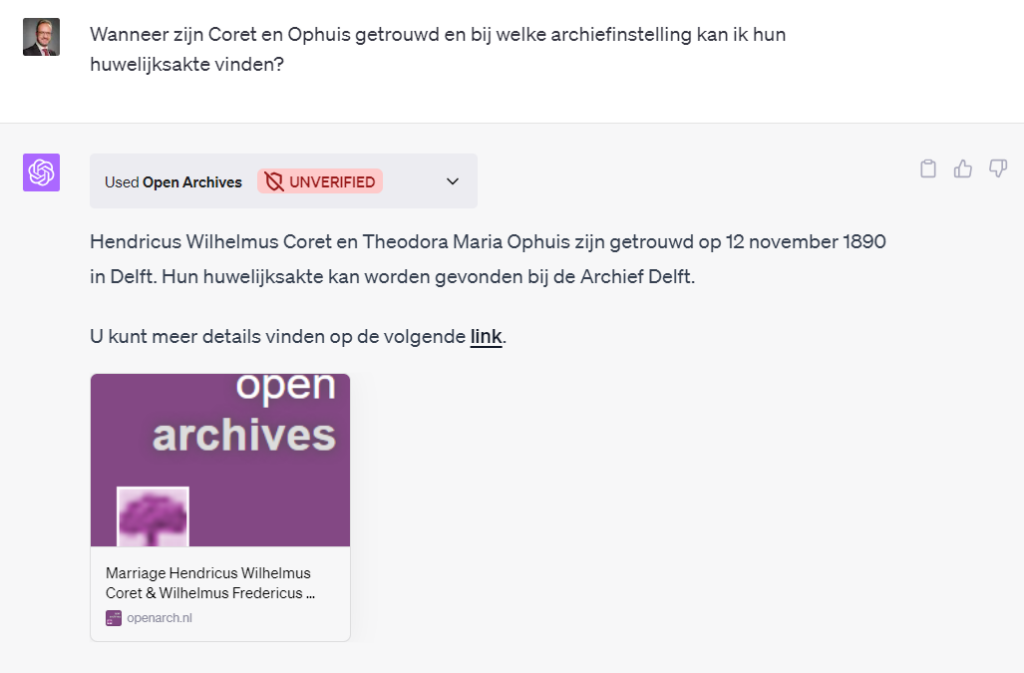
In de volgende vraag hebben de resultaten allemaal betrekking op Hendricus Wilhelmus Coret en is het dus logisch om de brontype (en archiefinstelling) op te sommen. Toch knap van ChatGPT.
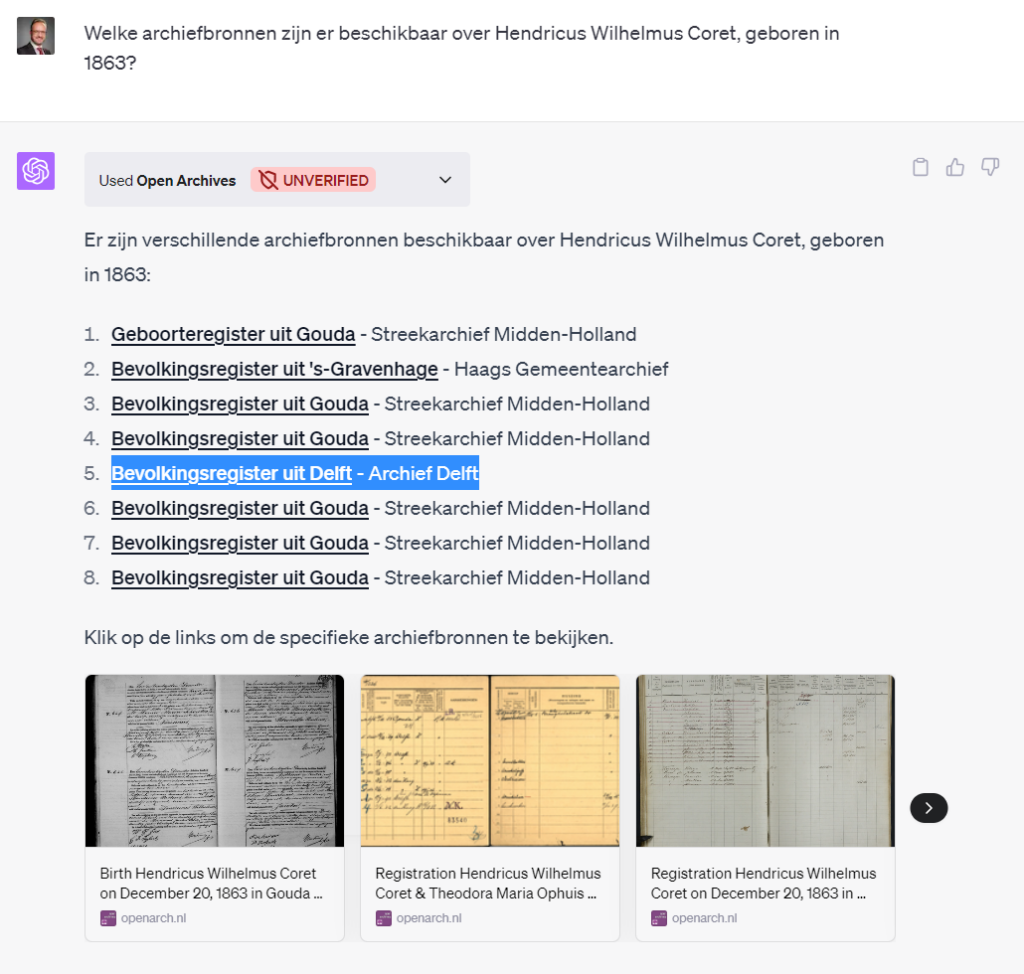
Dat ChatGPT de volgende vraag heeft beantwoord vind ik erg knap. ChatGPT weet dat het geboorteakten kan opvragen en overlijdensakten. ChatGPT heeft begrepen dat het de leeftijd van de persoon moest berekenen (om de “hoe oud” vraag te beantwoorden) en daarvoor de (metadata van de) geboorteakte en de (metadata van de) overlijdensaktes moet ophalen (je ziet in de GUI dat er 2 requests naar Open Archieven zijn gedaan!!!) van de persoon en dan de twee datums van elkaar moet halen. ChatGPT is niet helemaal zeker van de zaak, het verwacht een hogere leeftijd. Het gaat hier echter om een jong overleden kind, dat inderdaad maar enkele maanden oud is geworden.
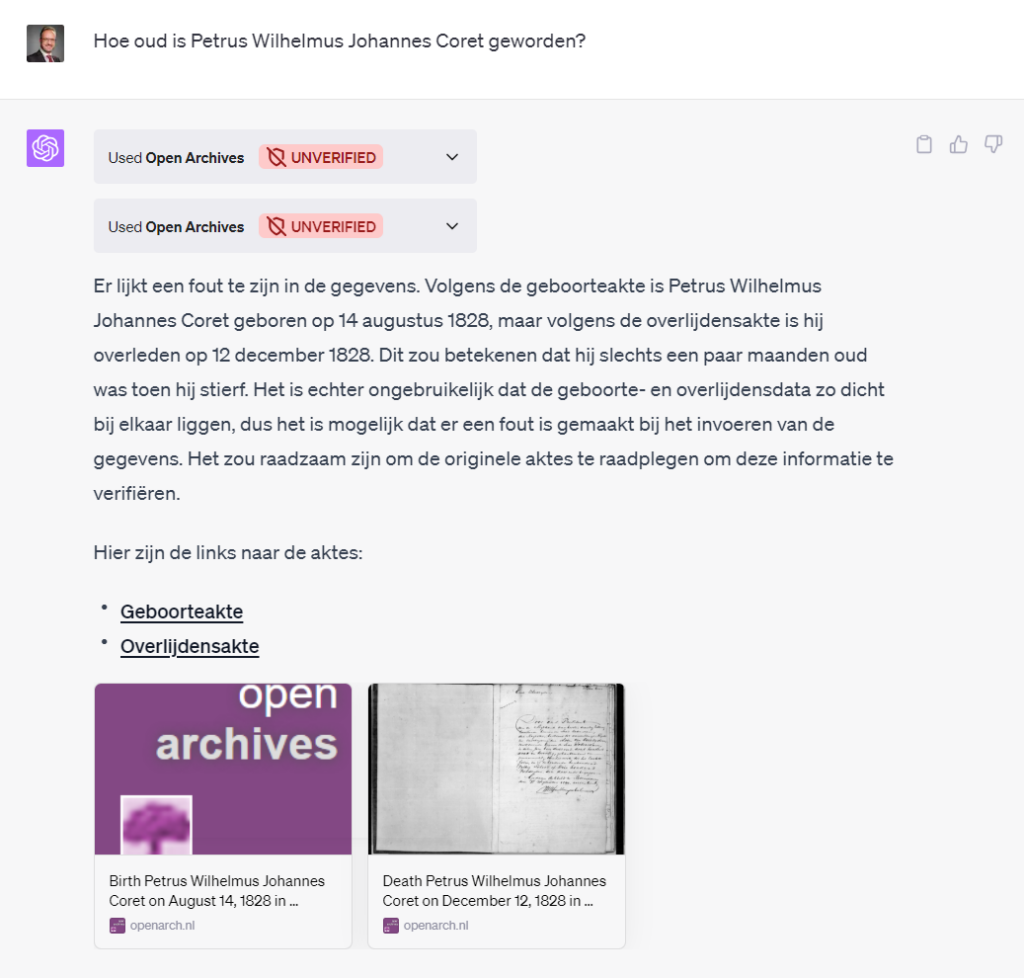
De resultaten van de API worden standaard gesorteerd op naam (en ik heb ChatGPT nog niet via de Open API YAML vertelt dat hier een parameter voor is). Maar in je prompt kun je natuurlijk iets over de volgorde opnemen. Ook kun je vragen de gegevens te “verrijken”, in dit geval met de weekdag (op basis van de datum). Van de 10 weekdagen is er (door handmatige controle via de Kalender omzetter) één incorrecte weekdag: 14 juni 1834 was een zaterdag (niet een vrijdag). Ook de sortering is niet perfect, 7. en 8. hadden omgekeerd moeten worden.
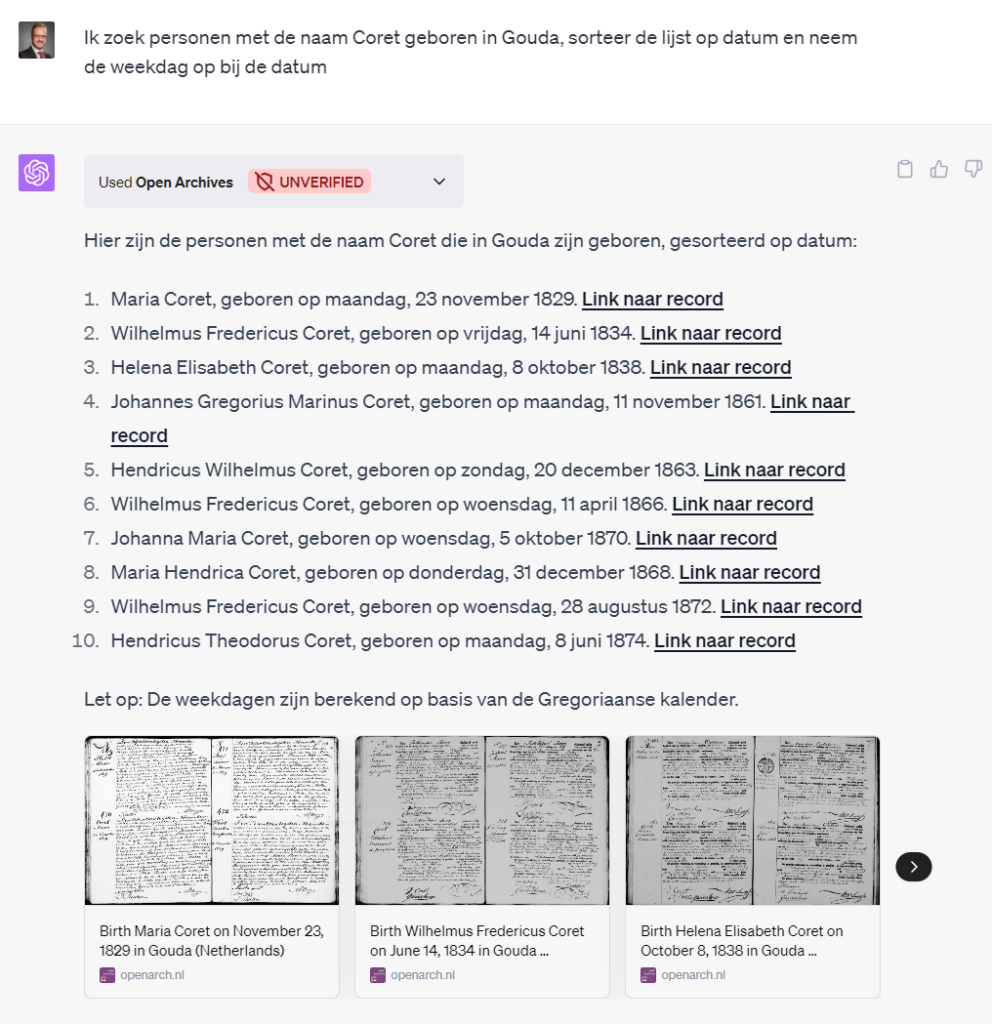
Bij de volgende vraag gaat ChatGPT de mist in. Ik vraag om de leeftijden van Goudse Coretten, dus ChatGPT gaat voor alle Coretten geboren in Gouda ook de overlijdensakten opvragen, maar zoals elke genealoog weet is puur ‘matchen’ echt niet genoeg. Vandaar in de tabel enkele personen ouder dan 100 jaar (en dat vindt ChatGPT niet raar?). De gevraagde gemiddelde leeftijd wordt niet geleverd.
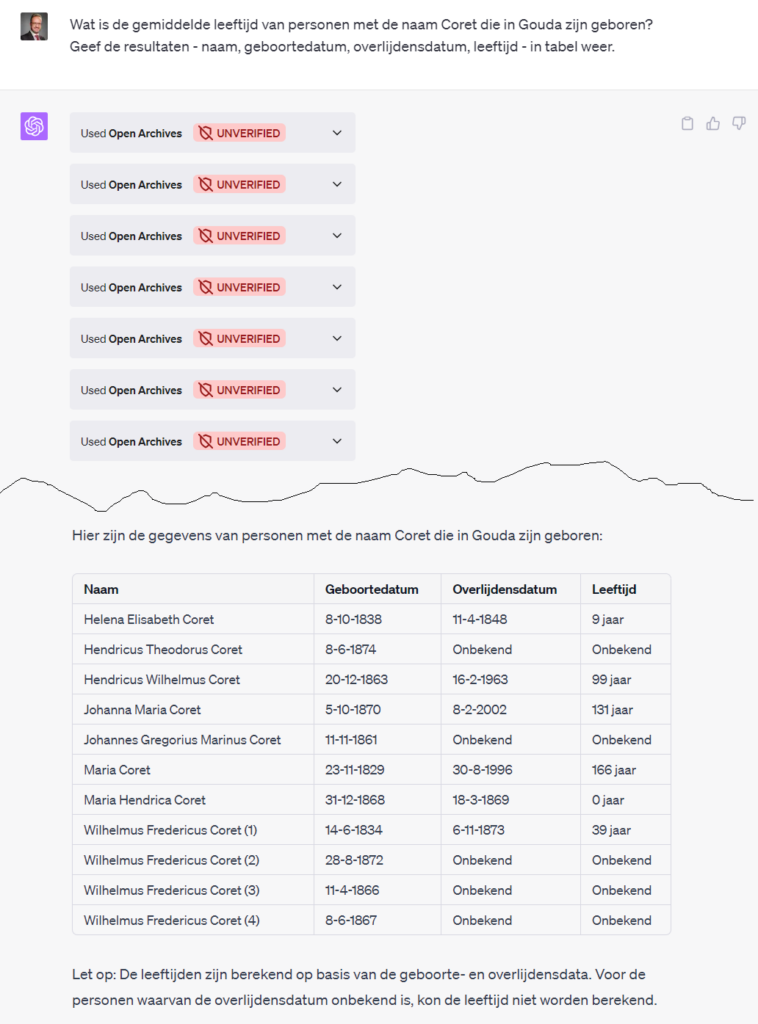
Sommige van de API methodes vereisen dat er een specifieke GUID (en archive_code) van wordt opgegeven, normaliter uit een eerdere vraag. Ook dit lijkt ChatGPT te snappen, waardoor de vervolgvraag naar kinderen van een echtpaar ook (de goede request en) goede antwoord geeft.
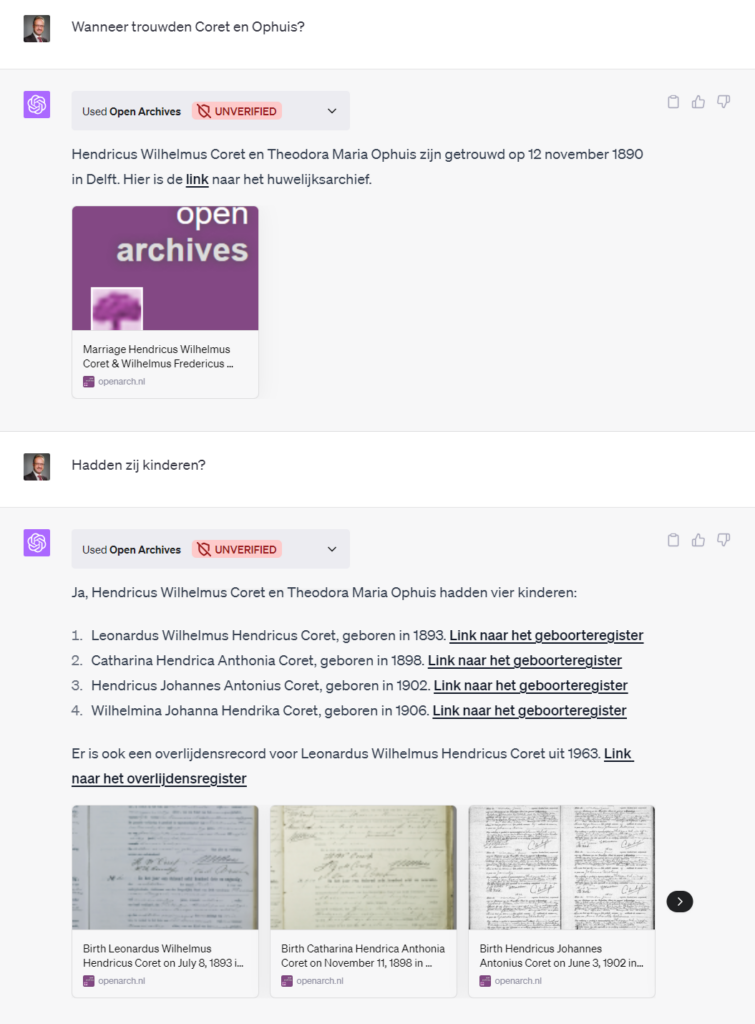
Zou het ook in een diagram getoond kunnen worden?
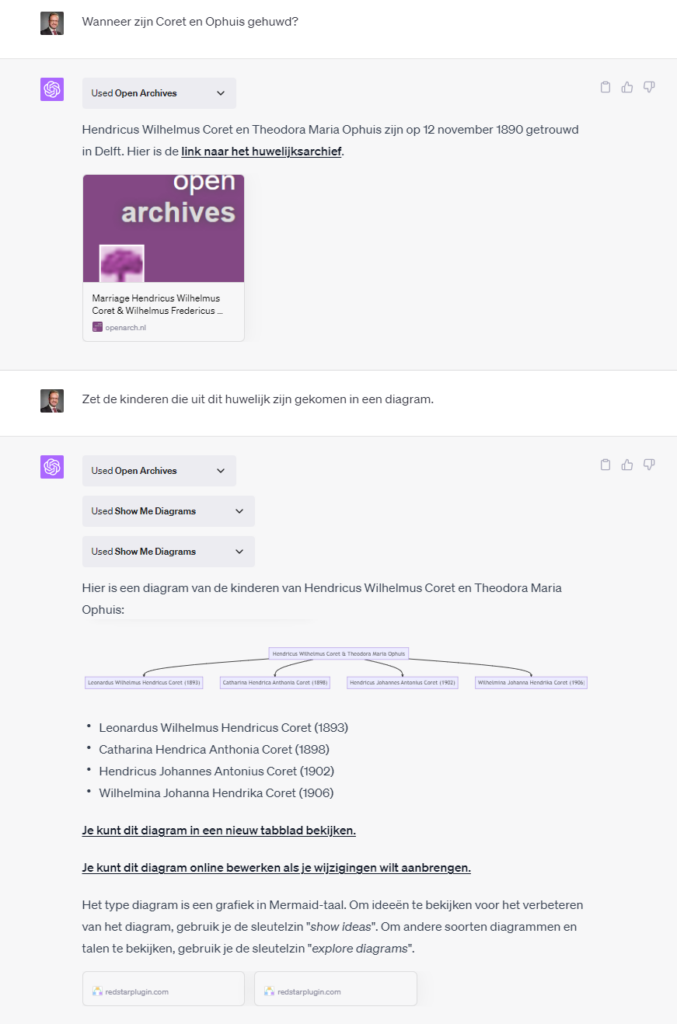
Weer een vrij eenvoudige vraag, maar net weergegeven antwoord.
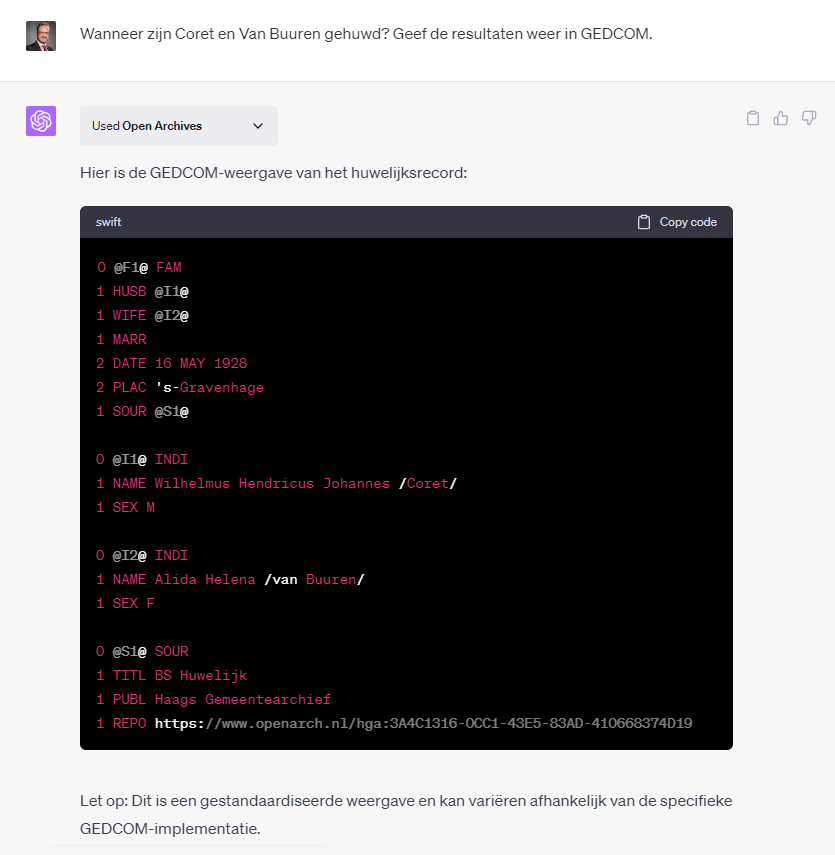
De resultaten kunnen ook in de genealogische defacto standaard GEDCOM gepresenteerd worden (niet geheel valide door ontbrekende header, 1 SOUR zou beter 2 SOUR moeten zijn):
De Open Archives plugin is zaterdagmiddag (17-6-2023) aangeboden aan ChatGPT. Op maandagmiddag is de plugin goedgekeurd en beschikbaar in de ChatGPT plugin store!

Das ist großartig! Ich freue mich sehr über dieses PlugIn! Allerdings habe ich es nicht geschafft irgendeine Antwort zu bekommen. Es kam immer “keine Ergebnisse gefunden”. Beispielsweise:
Prompt: Suche nach Hofmeijer in OpenArchives.
ChatGPT:
REQUEST TO OPEN ARCHIVES
{
“name”: “Hofmeijer”,
“birthyear”: 1800,
“number_show”: 10
}
RESPONSE FROM OPEN ARCHIVES
{
“query”: {
“name”: “Hofmeijer”,
“birthyear”: 1800,
“lang”: “de”
},
“response”: {
“docs”: [],
“number_found”: 0
}
}
Bezüglich GEDCOM: Sie können ChatGPT bitten auch Header und Trailer zu erzeugen.
Ist das PlugIn Open Source?
Dag Bob,
Wow, wat goed zeg! Mooie toepassing van ChatGPT waar veel toekomstmuziek in zit, denk ik.
Ik vroeg me af of ChatGPT consistent is in haar antwoorden, d.w.z. of ze iedere keer precies hetzelfde antwoord geeft (mits er natuurlijk geen nieuwe data zijn bijgekomen). Dat lijkt me voor de reproduceerbaarheid van onderzoek van belang.
Heel erg tof om te zien Bob!
Hele fijne uitleg en goede voorbeelden.