Bij het door de crowd laten indexeren van archiefbronnen, geo-positioneren van afbeeldingen of het geo-refereren van kaartmateriaal wordt er veelal binnen een crowdsource platform een project ingericht. Hiervoor is enerzijds informatie nodig over de bron(nen), zoals naam, plaats, jaartal/periode en toegangsnummer/inventarisnummer(s). Anderzijds moeten de scans vanuit de bron geselecteerd worden en gekopieerd naar het crowdsource platform. Veel werk, waar ook een prijskaartje aan hangt. Kan dit niet efficiënter? Was het digitaal efgoed mantra niet “data bij de bron”?
Als we het hebben over metadata van beeldmateriaal en het presenteren van beeldmateriaal, dan hebben we het over IIIF.
IIIF, een afkorting van de International Image Interoperability Framework, is een verzameling standaarden die zijn ontworpen om afbeeldingen en andere visuele materialen gemakkelijker toegankelijk te maken op het internet. Deze standaarden zijn vooral nuttig voor bibliotheken, musea en andere instellingen die grote collecties digitale afbeeldingen beheren. Ze helpen bij het samenstellen, delen en inzoomen op hoge-resolutie afbeeldingen, en het aanmaken van annotaties.
Eén deel van IIIF is gericht op de interactie met de afbeeldingen zelf (IIIF Image API). Deze functionaliteit stelt gebruikers in staat om afbeeldingen op verschillende manieren te bekijken. Je kunt bijvoorbeeld inzoomen op een klein deel van een hoge-resolutie afbeelding zonder de hele afbeelding te moeten laden, wat nuttig kan zijn als je bijvoorbeeld een gedetailleerd kunstwerk of historisch document bekijkt. Je kunt ook afbeeldingen draaien, de kleur aanpassen, of een specifiek deel van een afbeelding selecteren.
Het andere deel van IIIF gaat over hoe deze afbeeldingen worden gepresenteerd (IIIF Presentation API), dit wordt vastgelegd in een manifest. Dit geeft onder andere een beschrijving van een collectie van afbeeldingen, de organisatie hiervan qua volgorde en een indicatie waar de afbeeldingen te vinden zijn. Het kan ook gaan om het combineren van afbeeldingen met andere soorten media, zoals tekst, audio of video, om een complexer verhaal of uitleg te creëren.
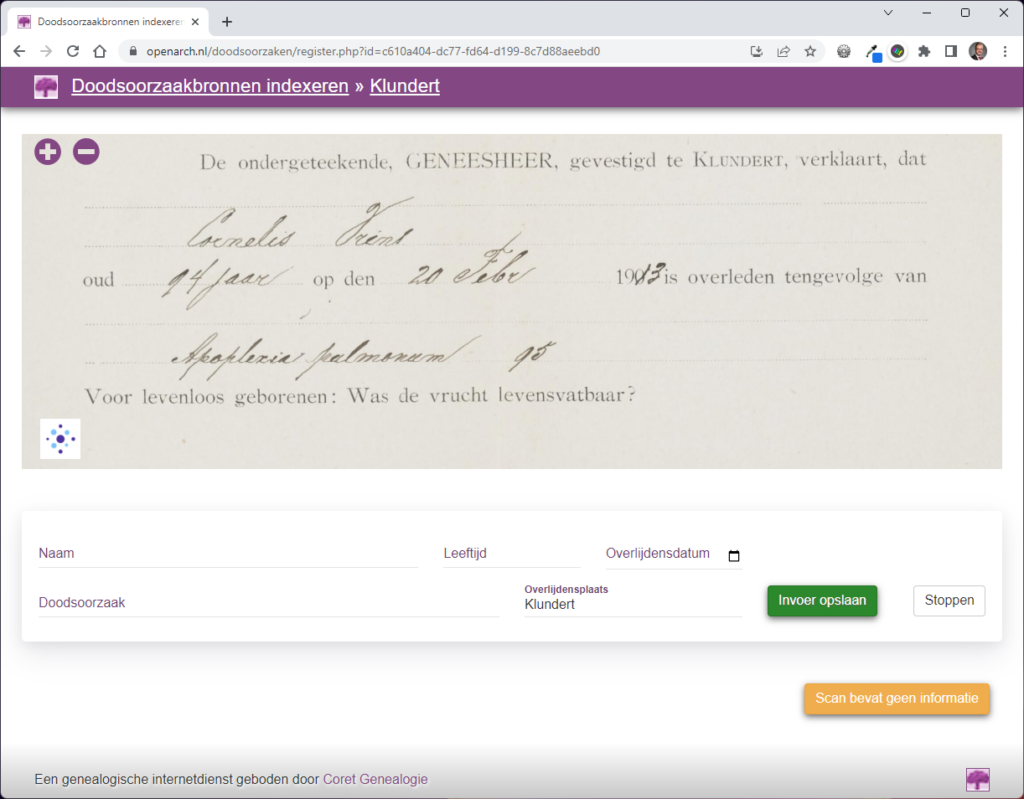
Stel, je wilt een crowdsourcingsplatform opzetten specifiek voor één type archiefbron: doodsbriefjes (overlijdensverklaringen waarop ook de doodsoorzaak staat vermeld). Als een archiefinstelling deze doodsoorzaakbronnen heeft gescand en als ‘registers met scans’ beschikbaar heeft gesteld dan kan de beschrijving (=metadata) uit het IIIF Manifest worden gehaald. In dit manifest staan ook de links naar de afbeeldingen, natuurlijk via een IIIF Image server. Doordat de archiefinstelling deze informatie over het beeldmateriaal op een standaard wijze toegankelijk maakt, kan het crowdsourcingsplatform deze doodsoorzaakbronnen zo als projecten aanbieden, waarbij de scans dus ‘geserveerd’ worden door de archiefinstelling, vanuit de bron (lees: het crowdsourcingsplatform heeft geen grote hoeveelheden storage nodig voor opslag van beeldmateriaal)!
En dan nu de praktijk. Bij welke systemen van archiefinstellingen die gescande doodsoorzakenbronnen hebben kan er een IIIF Manifest opgevraagd worden? Op dit moment komt Picturae’s Memorix als enige dicht in de buurt. Dit systeem biedt diverse API’s om data te ontsluiten. Helaas heb ik nog geen API documentatie gevonden, maar doordat de website van archiefinstellingen van Picturae klanten de API’s gebruiken, valt er snel te achterhalen welke API bevraagd moet worden om bijvoorbeeld informatie te krijgen over een register met scans. Dit komt in de buurt komt van een IIIF Manifest.
PS: onlangs is er in een Pica Verbonden Erfgoed project voor de beeldbank van de Atheneum Collecties door Picturae een mogelijk ingebouwd om een IIIF Manifest op te vragen, klik bijv. op het IIIF ikoontje in de linker balk bij de Hieronymusbrieven.
Zo levert een aanroep naar https://webservices.picturae.com/genealogy/register/d0e05ef2-bd60-86a9-0284-1ef349bed01d?apiKey=b80c5aec-ef5e-11e5-9ce9-5e5517507c66 (van het West-Brabants Archief) onder andere de volgende machine leesbare informatie (JSON):
register: [
{
id: "d0e05ef2-bd60-86a9-0284-1ef349bed01d",
tenant: "wba",
....
metadata: {
modified_time: "2022-11-23T11:06:38.566707",
type_title: "overlijdensoorzaken",
naam: "Gemeentebestuur Klundert 1811-1940 3096. (Medische) Verklaringen van overlijden, 1911.",
archiefnummer: "raw - 0451",
inventarisnummer: "3096",
brontype: "origineel",
gemeente: "Klundert",
periode: [ 1911 ],
has_assets: "register"
},
....
}
]En daarna kan Memorix bevraagd worden naar de scans binnen dit register, de zog. assets, via bijvoorbeeld het request https://webservices.picturae.com/genealogy/asset?apiKey=b80c5aec-ef5e-11e5-9ce9-5e5517507c66&page=1&q=register_id:%22d0e05ef2-bd60-86a9-0284-1ef349bed01d%22
asset: [
{
id: "9fa41342-159c-53f2-80e3-00376050b5c1",
file_id: "6eb5a89b-b76c-5039-3999-aabfd7a0c7c9",
....
title: "RAW04513096_00000",
metadata: {
....
},
thumb.small: "https://images.memorix.nl/wba/thumb/100x100/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9.jpg",
thumb.medium: "https://images.memorix.nl/wba/thumb/250x250/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9.jpg",
thumb.large: "https://images.memorix.nl/wba/thumb/640x480/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9.jpg",
topview: "https://images.memorix.nl/wba/topviewjson/memorix/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9",
download: "https://images.memorix.nl/wba/download/large/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9.jpg",
deepzoom: "https://images.memorix.nl/wba/deepzoom/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9.dzi"
},Via de assets krijgen we informatie over de directe links naar de plaatjes zodat deze als thumbnail of via een viewer die TopView of DeepZoom ‘spreekt’ kunnen laten zien, vanuit de bron. Liever nog had ik een link naar de IIIF info.json (IIIF Image API) geizen. Hoewel dit niet geadverteerd wordt, wordt de IIIF Image API wel ondersteund door Memorix. Je moet even weten hoe de URL wordt opgebouwd… Voor de hierboven genoemde asset is de (basis) URL voor de IIIF Image API https://images.memorix.nl/wba/iiif/6eb5a89b-b76c-5039-3999-aabfd7a0c7c9
Voor het in oprichting zijnde crowdsourcingsplatform doodsoorzaken.nl is de informatie over de registers met ‘doodsbriefjes’ opgehaald bij het West-Brabants Archief via de API en worden er binnen dit platform scans getoond vanuit de bron (via de IIIF Image server). Een archiefinstelling die haar data en scans zo toegankelijk maakt kan je als platform toch geen kosten meer in rekening brengen?

mooi dat het nu live is – de IIIF ondersteuning van Memorie Maior / Picturae – https://athenaeumcollecties.nl/collecties/gedigitaliseerde-collecties/manifest/08e4dbc1-3cd8-a59c-a5d8-04ba786387c0