Een pipeline en viewer voor een transcriptieportal
Nu er meer en meer archiefinstellingen aan de slag gaan met handschriftherkenning, de logische stap in het digitaliseringsproces, was het tijd voor Open Archieven om naast (historische) persoonsvermeldingen ook transcripties integraal doorzoekbaar te maken en te presenteren: een transcriptieportal, hoe moeilijk kan dat zijn?
De logische ingrediënten voor een transcriptieportal zijn transcripties, afbeeldingen en voor de bronvermeldingen/navigatie natuurlijk ook archiefbeschrijvingen. Alle drie de bronnen zijn in een toenemend aantal online te vinden. Tenminste als je goed zoekt, enige tijd reserveert voor de nodige transformaties én tenslotte geduld hebt om de nodige aanvullingen te verkrijgen. De pipeline die nu staat, maakt dat niet transcripties relatief snel toegevoegd kunnen worden aan Open Archieven.
Transcripties
De eerste grote bron van transcripties was project IJsberg, waar Regionale Historische Centra een (klein) deel van hun gescande notariële akten en het Nationaal Archief grote delen van de VOC archieven ingebracht hebben om via Transkribus voorzien te worden van transcripties met een lage Character Error Rate (dus redelijke hoge kwaliteit) te verkrijgen. Via de projectwebsite kunnen deze transcripties doorzocht worden. Onlangs heeft het Nationaal Archief deze dataset uitgebreid (versie 8.1) met transcripties die “in house” zijn gemaakt met het door het KNAW Humanities Cluster ontwikkelde Loghi. Er is ook een viewer ontwikkeld door het Nationaal Archief, deze is beschikbaar als open source (hierover later meer).
Twee andere grote bronnen van transcripties zijn in projecten van KNAW Huygens Instituut gerealiseerd: REPUBLIC en GLOBALISE. Beide projecten werken op materiaal dat het Nationaal Archief reeds heeft gescand; de Huygens projecten maken de transcripties met Loghi en passen ook technieken als Named Entity Recognition (NRE) toe om namen, data en plaatsen te herkennen in de transcripties. Beide projecten hebben een eigen projectwebsite en elke eigen viewer ontwikkeld om de transcripties en NER te tonen.
Enthousiast gemaakt door de goede HTR resultaten zijn er diverse archieven die gebruik maken van Transkribus om de tekst in handgeschreven documenten te lezen en deze transcripties ook in de Transkribus omgeving te tonen (want uitdaging voor menig archief: hoe krijg ik al dit materiaal in mijn archiefbeheersysteem en kan ik het in mijn eigen omgeving tonen?).
Hieronder een overzicht van de bronnen die de ingest pipeline van Open Archieven in gaan:
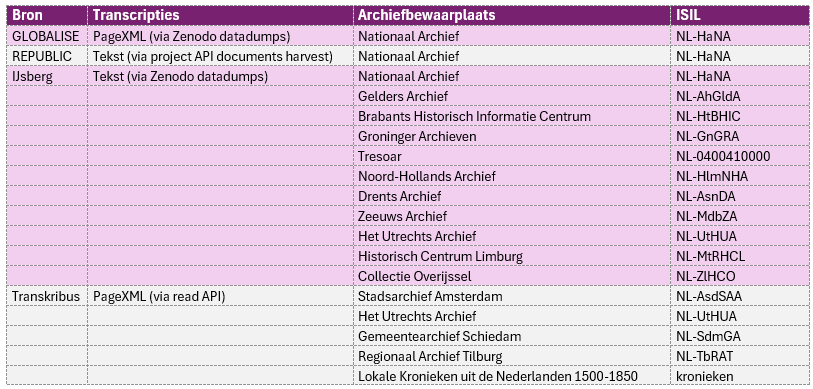
Het leek voor de pipeline handig om te werken met de ISIL-codes van de archiefbewaarplaatsen (=de “leveranciers van de scans”), te meer omdat deze in veel projecten worden gebruikt in de naamgeving van de scans en/of transcripties. Tot je dan weer een Kronieken uit de Nederlanden initiatief van de Universiteit Leiden en de Vrije Universiteit bij Transkribus tegenkomt. Dit samenwerkingsverband heeft geen ISIL. Maar nog lastiger, de bronnen komen vanuit een groot aantal archiefbewaarplaatsen in Nederland en België (later meer hierover).
Het is goed te zien dat meer en meer initiatieven open data bieden (op verzoek en zelfs pro-actief), ook qua transcripties! Zo heeft project IJsberg datadumps op Zenodo geplaats (link) en GLOBALISE biedt haar datadumps aan via Dataverse (link). GLOBALISE heeft hiervan ook een nette datasetbeschrijving gemaakt die is aangemeld bij het Datasetregister!
Voor het wat oudere REPUBLIC moesten de transcripties “geharvest” worden via de API van het project. Hopelijk binnenkort ook op Zenodo of Dataverse (te meer daar er een een nog grotere hoeveelheid transcripties is aangekondigd).
Transkribus is een platform voor HTR die ook een “voorkant” biedt én een API. Deze (ongedocumenteerde) Search & Read API geeft de Transkribus webapplicatie en dus alle hergebruikers open toegang tot de transcripties van een collectie (de identifiers van deze collecties kun je uit de netwerk requests van de “voorkant” halen of navragen bij de collectie beheerder). Via de API kunnen deze transcripties dus zeer eenvoudig geharvest worden (en omdat de “Transkribus archieven” nog steeds scans toevoegen wordt deze bron dikwijls gecontroleerd op nieuwe transcripties).
Maar, de transcripties komen wel in verschillende vormen! In PageXML en/of platte tekst. De voorkeur gaat uit naar PageXML omdat deze bestanden de locatie van woorden/zinnen op de scan bevat, iets wat natuurlijk van belang is in de viewer van een transcriptieportal. Zoals in de 2e kolom van tabel 1 valt af te lezen is een gedeelte van de transcripties in PageXML beschikbaar, dus kan in een “scans naast transcriptie” viewer worden getoond, van de rest kunnen de transcripties alleen “los” van de scan getoond worden.

Afbeeldingen
In een transcriptieportal wil je afbeeldingen tonen, een thumbnail in de zoekresultaten en de mogelijkheid om de scan in “al haar glorie” te bekijken. Ook bij de afbeeldingen dient er weer rekening gehouden te worden met diverse “aanvliegroutes”: IIIF of niet.

IIIF is een framework met diverse standaarden omtrent afbeeldingen, waar twee belangrijke de IIIF Image API en de IIIF Presentation API zijn. De Image API standaardiseert de wijze waarop je (een deel van) een afbeelding aan een IIIF resource aan de provider kunt vragen. Een reeks producten kan afbeeldingen volgens de IIIF Image API bieden. De grote spelers in deze context – het Nationaal Archief en Transkribus – bieden alle afbeeldingen via IIIF aan. Deze standaard maakt het voor dienstverleners als Open Archieven een stuk makkelijker om de scans (vanuit de bron!) te tonen in een viewer.
IIIF is dan ook een must / no-brainer bij de ontwikkeling van een viewer. De transcripties vormen een laag met annotaties die (simpel gezegd) gekoppeld wordt aan de scan en je beide in één keer kunt bekijken (zie figuur 1). Open Archieven maakt dankbaar gebruik van de binnen project IJsberg ontwikkelde viewer, waarbij de look-and-feel meer in Open Archieven stijl is veranderd.
De benodigde koppeling tussen scan en transcripties is helaas nog niet zo eenvoudig. Deze data wordt nog niet gezien als iets dat je als dataset of via een API beschikbaar kan/moet stellen aan de wereld. De GLOBALISE PageXML deed het hier goed, deze bevatte per transcriptie een deel van de koppeling met de scan, het andere deel kon uit de EAD’s van het Nationaal Archief worden gehaald (bedankt Leon voor dit inzicht!).
Voor de andere Nationaal Archief bronnen, zoals project IJsberg, ontbrak de koppeling. De transcripties zijn systematisch van een naam voorzien, zoals NL-HaNA_1.05.11.14_582_0214 (= ISIL _ archieftoegang _ inventarisnummer _ volgnummer). Dit voorbeeld heeft betrekking op een scan waarvan de IIIF info.json de volgende URL heeft:
https://service.archief.nl/iip/fb/ac/02/db/5f/39/43/5a/b7/bf/0e/b5/41/86/7c/1c/c5f7fb4a-0ff2-45d4-a966-3126470c0aca.jp2/info.json
Een vraag aan het Nationaal Archief (d.d. 26 maart 2024) hoe ik grote aantallen (1M+) scannamen kan omzetten in het juiste IIIF info.json adres is nog onbeantwoord. Op dit moment “peuter” ik deze informatie uit de website, wat met ongeveer 100.000 per dag, enig geduld vereist (op moment van schrijven staan er nog zo’n 350.000 in de queue om losgepeuterd te worden).
Transkribus geeft via de API de juiste informatie om de transcriptie aan de scan te koppelen en biedt de scans aan via IIIF!
Maar de afbeeldingen worden op meer manier door archiefinstellingen getoond aan het publiek: via archieven.nl en de Memorix beeldbank. Om met de laatste te beginnen: de Memorix beeldbank ondersteunt al lange tijd – stilzwijgend – de IIIF Image API. Memorix-gebruikers bieden de transcripties alleen in tekstvorm aan, dus de Open Archieven viewer kan alleen de scan “inzoombaar” tonen, zonder transcriptie. Archieven.nl biedt afbeeldingen nog niet via de IIIF Image API aan. Via een custom harvester worden de URL’s van de thumbnails (en links naar viewer) bemachtigd, zodat deze in de zoekresultaten op Open Archieven getoond kunnen worden. Voor de afbeeldingen die via archieven.nl worden ontsloten kan er (door ontbreken IIIF Image API ondersteuning) dus alleen een link worden geboden op Open Archieven naar de custom viewer op archieven.nl (zonder transcripties).

Archiefbeschrijvingen
Op Open Archieven wordt alle informatie voorzien van een “rijke” archiefbeschrijving. Zo wordt er een logo van de archiefbewaarplaats getoond, een beschrijving van de archieftoegang en het inventaris, waar mogelijk voorzien van links naar archieftoegang en inventaris op de bronwebsite.

Archiefbeschrijvingen worden gepubliceerd in het EAD (XML) formaat, althans door sommige archiefinstellingen, zoals het Nationaal Archief en archieven die gebruik maken van Memorix. Dit maakt het vergaren van informatie voor de bronvermelding redelijk eenvoudig.
Een enkele archieven.nl gebruiker heeft mij op verzoek via e-mail een EAD bestand toegestuurd, daar deze nog niet als “open” gemarkeerd was en dus ook niet op opendata.archieven.nl beschikbaar was. Andere archieven.nl gebruikers reageerde dat zij geen EAD konden aanleveren?! Voor deze archiefinstellingen, alsook instellingen die nog een ander archiefbeheersysteem gebruiken, is de tekst van de beschrijving per inventaris per archieftoegang (deels handmatig) “gescraped”. Een deel van deze gescrapte beschrijvingen mist de URL naar de beschrijving bij de bron. Voor het transcriptieportal betekent dat niet alle inventarissen van een link naar de bron konden worden voorzien.
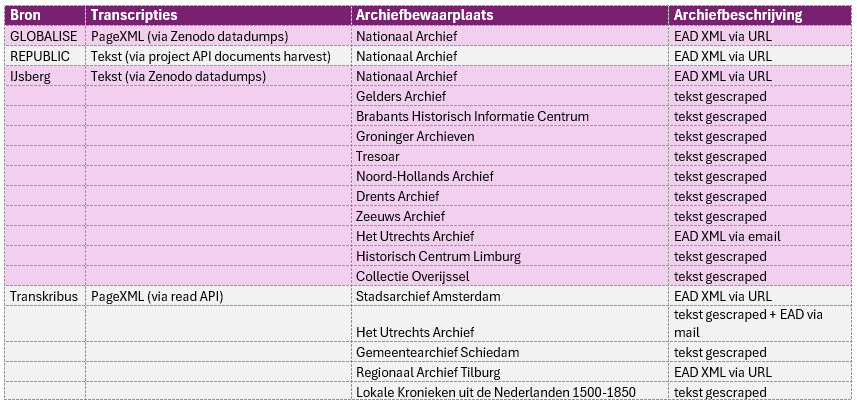
Voor de eerdere genoemde Kronieken uit de Nederlanden waren er bronvermeldingen op Transkribus, sommige met link naar de bron opgenomen op Transkribus. Helaas in vrij tekst vorm, dus niet machineleesbaar. En dat is lastig, daar in deze “virtuele collectie” bronnen voorkomen van Athenaeum Bibliotheek Deventer, Collectie Overijssel, DBNL.org, Fryske Akademie, GA Zaanstad, Gelders Archief, Gemeentearchief Schouwen-Duiveland, Gemeentearchief van ’s-Gravenhage, Historisch Centrum Limburg, Huijgens Instituut, KB Brussel, KB Den Haag, Noord-Hollands Archief, Privébezit, Regionaal Archief Alkmaar, Rijksarchief Hasselt, Rijksarchief te Kortrijk, Stadsarchief Amsterdam, Stadsarchief Antwerpen, Stadsarchief Breda, Stadsarchief Brugge, Stadsarchief Brussel, Stadsarchief Dordrecht, Stadsarchief Gent, Stadsarchief Kampen, Stadsarchief Leuven, Stadsarchief Mechelen, Stadsarchief Rotterdam, Streekarchief Voorne-Putten Rozenburg, Tresoar, Twentse Taalbank, UB Gent, UB Tilburg, Ugent, Universiteit Leiden en Westfries Archief. Voor de navigatie door bronnen op Open Archieven (dus archiefbewaarplaatsen, archieftoegangen en inventarissen), gooien de ‘kronieken” wat roet door het gestructureerde eten.

Conclusie
Meer en meer data en afbeeldingen worden op een machineleesbare wijze gepubliceerd voor hergebruik. Open Archieven kan hiermee voor haar doelgroep – met name stamboomonderzoekers – weer een mooie functionaliteit bieden: het integraal doorzoeken van (op dit moment) 8,8 miljoen getranscribeerde documenten en deze op een aantrekkelijke wijze presenteren. De onderliggende pipeline is klaar voor de groei van door HTR gemaakte transcripties.
Wat mij bij transcripties altijd tegenvalt is dat ik ze vaak niet begrijp. De juridische taal, het oud-Hollands en de HTR-foutjes maken het begrijpen van documenten uit de 16de – 18de eeuw best lastig. Als experiment kunnen Open Archieven abonnees de hulp inroepen van kunstmatige intelligentie! Taalmodellen (LLM) lijken goed in staat om begrijpelijke samenvattingen te maken van de transcripties in hedendaags Nederlands (en Engels, Duits en Frans, want Open Archieven wordt in 4 talen aangeboden). Op deze wijze helpt de computer ons niet alleen via HTR met het lezen van de transcriptie maar met het beter begrijpen! Zie ook de aankondiging van deze nieuwe functionaliteit in de Open Archieven Nieuwsbrief 2024-05.


Kanonne, mooi werk Bob,
Herkenbaar, Bob. Ik heb voor de Anne Frank Stichting een vergelijkbaar traject doorlopen om een deel van de (juridisch beschermde) collectie full-tekst doorzoekbaar te maken. Daarbij hebben we hulp ingeschakeld van Gijsjan Brouwer. Als je interesse hebt, demonstreer ik je graag het eindresultaat en de manier waarop we beheer voeren over de collectie.