De nieuwste versie van triplestore GraphDB (10.3) heeft nu ook een integratie met ChatGPT. Na installatie van deze nieuwe versie, met een (betaalde) API key van OpenAI en de documentatie kon ik snel aan de slag om te kijken wat “harnass the power of ChatGTP” betekent. NB: Bijna alle tests hebben betrekking op de Gouda Tijdmachine Knowledge Graph.
SPARQL query uitleg
Wanneer je een SPARQL query uitvoert in GraphDB door op de Run knop én de Alt toets te drukken, dan zal in de resultaten een _gpt kolom verschijnen met de uitleg van de query:
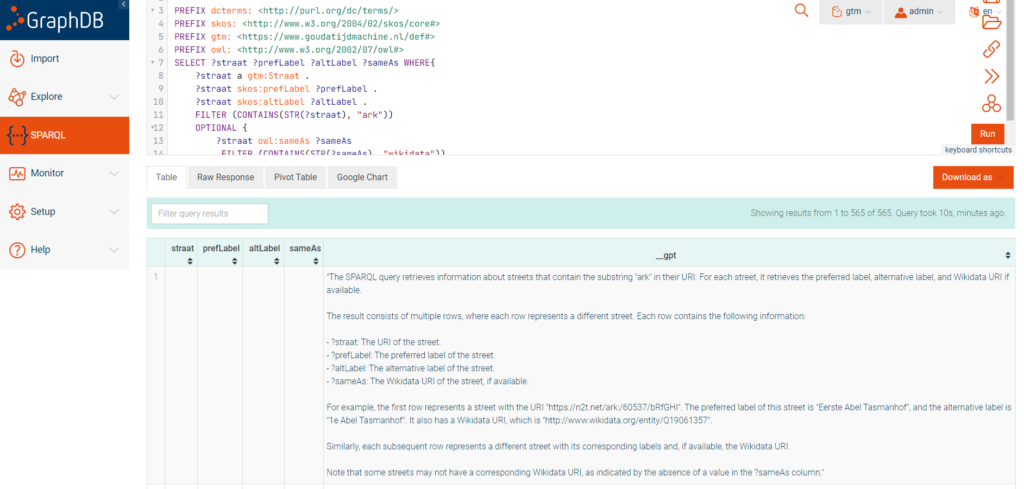
ChatGTP inzetten voor reconcilitatie?
Naar aanleiding van een gesprek eerder op de dag, in hoeverre AI erfgoedinstellingen kan helpen bij het reconciliëren van termen (dus termen zoals plaatsnamen, kunstenaars, schrijvers, ed. koppelen aan URI’s in terminologiebronnen) een test waarop ik al wist dat het antwoord niet goed zou zijn (maar toont wel een manier aan waarop je ChatGPT aangesproken kan worden in GraphDB’s SPARQL):
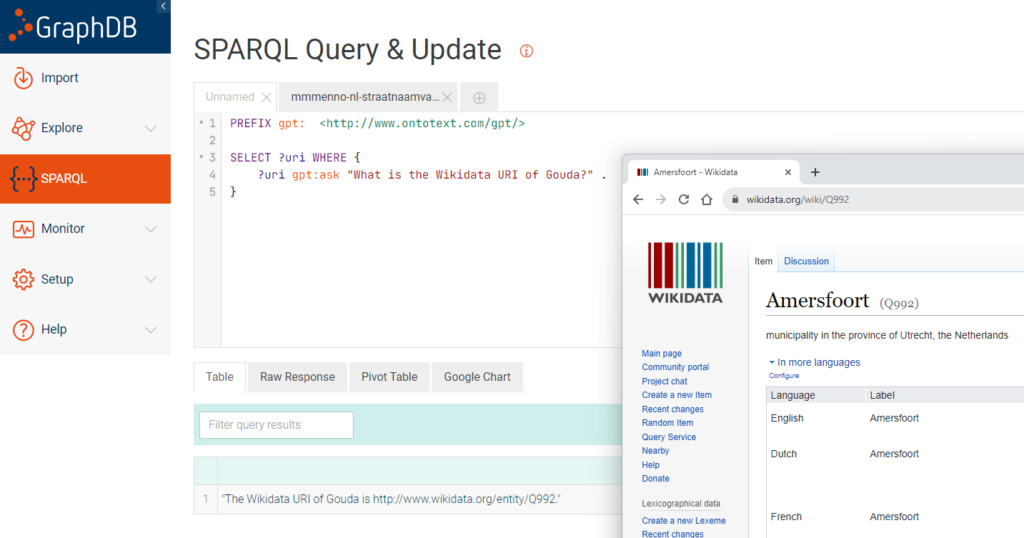
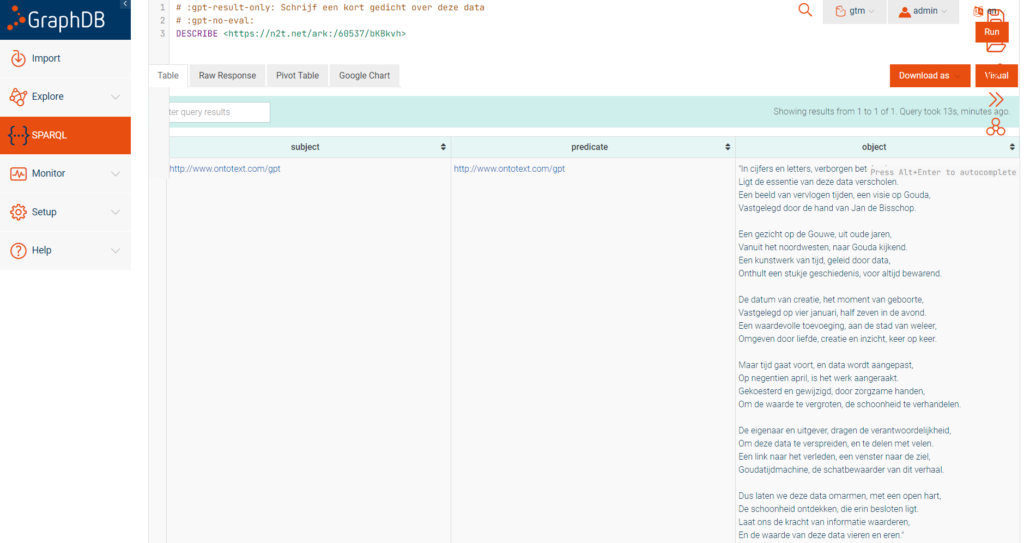
Maak iets van mijn data (1)
De SPARQL functie DESCRIBE geeft alle triples van een bepaald subject, in dit voorbeeld van een pen en perceeltekening getiteld “Gezicht op de Gouwe”. In dit voorbeeld geef ik de instructie via een tweetal “commentaar-commando’s” om een kort gedicht te maken over het werk (mijn verzoek is in het Nederlands, dus is het antwoord ook in het Nederlands).
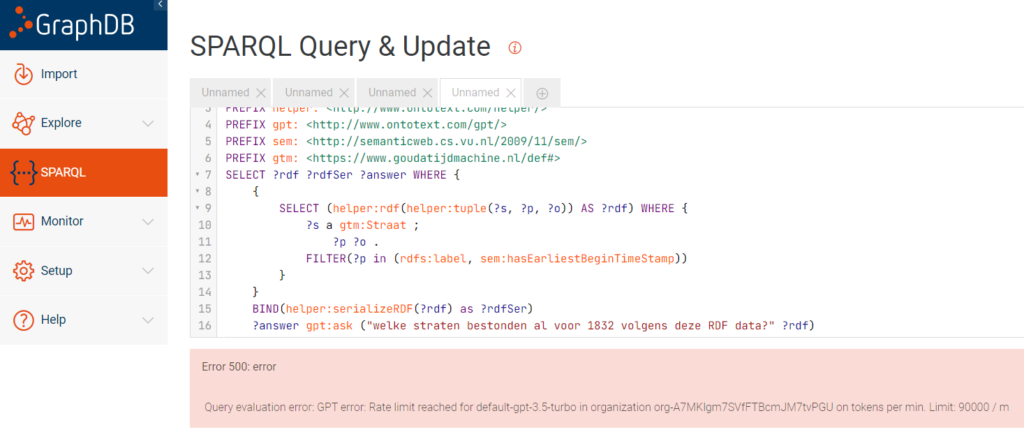
Stel vragen aan mijn data in natuurlijke taal, sort-of
Je kan ook via helper functies triples verzamelen (in dit geval de sem:hasEarliestBeginTimeStamp waarden van de Goudse straten) om daar dan een een vraag over te stellen. Helaas, de verzamelde triples waren te veel “tokens” voor het gebruikte model. (een LIMIT 20 in de query had enige uitkomst geboden, maar toont nog wel de zwakte, liever had je, in plaats dat je alle RDF-kennis in je ChatGTP query moet stoppen, dat de vraag werd omgeschreven in SPARQL)
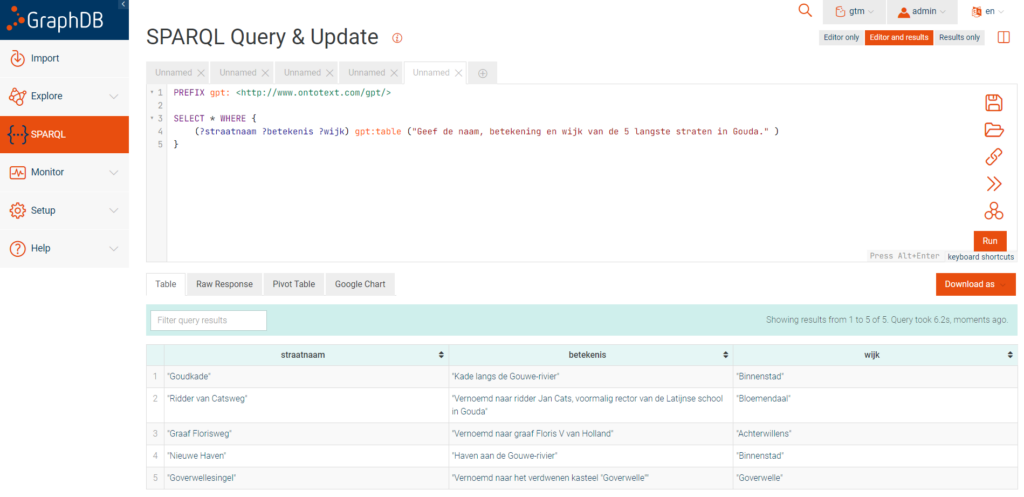
Data van ChatGTP in tabel vorm
Je kunt ook een vraag stellen aan ChatGPT waarbij de antwoorden in “tabel vorm” beschikbaar komen binnen je SPARQL query. In dit voorbeeld wordt er niets met het resultaat gedaan, alleen getoond. En de kenners zullen glimlachen van het antwoord (lees: hallucinaties).
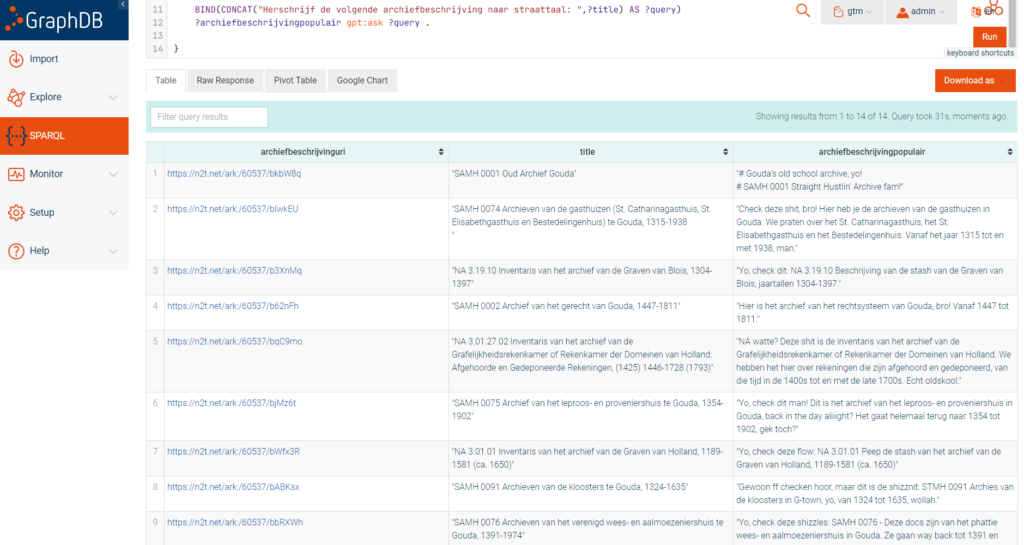
Maak iets van mijn data (2)
OK, mijn bijdrage om archieven populairder te krijgen bij de jeugd (of: hoe krijg je archivarissen op de kast 😉
Conclusie
Het speelkwartier is weer voorbij. Nuttige toepassingen heb ik nog niet zo 1,2,3 gevonden voor deze integratie, het is meer in de categorie “leuk” zoals we van een Large Language Model mogen verwachten.
Ik denk dat ik had gehoopt dat ik een vraag in natuurlijke taal kon stellen die dan op basis van de Gouda Tijdmachine Ontologie werd omgeschreven in SPARQL en uitgevoerd en resulteert in een antwoord in natuurlijke taal zou opleveren. Benieuwd wat de vorderingen van Kadaster & Friends zijn naar aanleiding van hun publieksprijswinnende Hackalod 2022 project…

Bob, thank you for giving it a try. Indeed, this integration cannot overcome the intrinsic limitations of ChatGPT. One scenario that could be useful (and you haven’t commented above), is to use GraphDB-ChatGPT integration to summarize the results of a query. You get the results in natural language – a paragraph of text, elaborates on what’s in the vanilla SPARQL results table. We are thinking of productizing the NL-to-SPARQL – it’s useful, when you are using good popular ontology
p.s. Sorry for answering in Engish, but my Dutch is as good as your Bulgarian 🙂