Diverse archieforganisaties zijn actief op het gebied van Handwritten Text Recognition (HTR). Hiermee kunnen onder andere automatisch transcripties gemaakt worden van handgeschreven documenten. En dat klinkt natuurlijk mooi, nog meer archiefstukken die inhoudelijk doorzocht kunnen worden. En toch bekruipt mij een naar gevoel, kunnen archieven wel omgaan met deze extra inhoud ?
Archieven worden veelal toegankelijk gemaakt via archief- en inventarisbeschrijvingen of nadere toegangen (indexen). Een archiefgebruiker kan dus zoeken in de teksten van de beschrijvingen (de metadata) of specifieke geëxtraheerde inhoud als namen, plaatsen en datums.
Doorzoek je de 100 miljoen pagina’s uit Nederlandse kranten, boeken en tijdschriften via Delpher dan wordt echt de inhoud van deze bronnen doorzocht. Door de toegepaste Optical Character Recognition (OCR) kan de computer is vele gevallen redelijk goed de tekst “lezen” (en dus doorzoeken).
Delpher is ontwikkeld en wordt beheerd door de Koninklijke Bibliotheek, die daartoe samenwerkt met diverse bibliotheken en instellingen. Vreemd genoemd komt er in het rijtje van partners geen enkele archieforganisatie voor. Wel zijn er diverse archieforganisaties die hun krantencollectie via Delpher beschikbaar stellen. En dan te bedenken dat kranten, boeken en tijdschriften qua auteursrechten vele malen lastiger zijn dan openbare archiefstukken.
Waarom passen archieforganisaties geen OCR toe om hun gedigitaliseerde collecties (anders dan kranten) op inhoud doorzoekbaar te maken? Is de hoeveelheid scans wellicht te laag dat men deze inhoud niet verder uit nut? Om hier een beeld van te krijgen is er via archieven.nl (dat ruim 70 organisaties bedient) gekeken naar het totaal aantal archiefstukken, het aantal dat hiervan is gedigitaliseerd en het totaal aantal bestanden.
De top 10 op basis van percentage gedigitaliseerde archiefstukken ziet er als volgt uit:
| Organisatie | Gedigitaliseerd |
| Stadsarchief Deventer | 23,3% |
| Gemeentearchief Vlissingen | 18,4% |
| Zeeuws Archief | 18,0% |
| Het Utrechts Archief | 15,3% |
| NIOD Instituut voor Oorlogs-, Holocaust- en Genocidestudies | 14,0% |
| Rijckheyt, centrum voor regionale geschiedenis | 13,6% |
| Hoogheemraadschap van Delfland | 13,4% |
| Regionaal Historisch Centrum Vecht en Venen | 13,0% |
| Gelders Archief | 11,7% |
| Noord-Hollands Archief | 10,7% |
Sorteer je de verzamelde statistieken op het aantal bestanden dan ziet de top 10 er als volgt uit:
| Organisatie | Aantal bestanden |
| Gelders Archief | 6.351.612 |
| Het Utrechts Archief | 4.706.926 |
| Brabants Historisch Informatie Centrum (BHIC) | 3.657.891 |
| Noord-Hollands Archief | 2.663.502 |
| Zeeuws Archief | 2.132.903 |
| Historisch Centrum Overijssel (HCO) | 2.035.044 |
| Regionaal Archief Dordrecht | 2.020.549 |
| Westfries Archief | 1.775.302 |
| Regionaal Archief Rivierenland | 1.368.070 |
| Regionaal Historisch Centrum Limburg (RHCL) | 1.290.042 |
Let wel: “bestand” kan niet één op één vertaald kan worden naar “scan van een pagina”. Onder andere bij het Haags Gemeentearchief zijn sommige bestanden containers in PDF formaat. Dergelijke PDF bestanden bevatten tussen de 80 en 240 scans. Waarom archieforganisaties de scans in PDF containers ter beschikking stellen aan het publiek is mij niet duidelijk. Gebruikersvriendelijk is het in ieder geval niet.
Enkele van de genoemde PDF bestanden bevatten meer dan alleen scans: er is ook inhoud van een OCR proces aanwezig. In de praktijk betekent dit dat een gebruiker het PDF bestand kan doorzoeken via de PDF lezer (welke tegenwoordig is ingebouwd in de browser) . Een functie die waarschijnlijk weinig gebruikt zal worden omdat gebruikers niet weten dat dat kan. Dat de PDF ook inhoud bevat van een OCR proces wordt nergens gemeld. En nog schokkender: deze waardevolle inhoud is niet doorzoekbaar via de website van de archieforganisatie …

Er zijn dus al heel wat scans beschikbaar bij archieforganisaties. Deels is dit materiaal handgeschreven, maar ook zeker een deel (met name 20e eeuw) is getypt of gedrukt materiaal. OCR kan dus op een deel van de scans worden toegepast om zodoende ook archiefmateriaal op inhoud te kunnen doorzoeken. Dat is toch, als ik alle HTR verhalen lees, wat we willen?
Ik vind het raar dat archiefstukken niet beter toegankelijk worden gemaakt via OCR. Aan de technologie hoeft het niet te liggen. De scans (eventueel geëxtraheerd uit PDF documenten) kunnen eenvoudig geautomatiseerd door een OCR-engine als Tesseract gehaald worden (en voorzien worden van relevante EXIF informatie). De aldus verkregen inhoud (aangevuld met locatiegegevens binnen het document op basis van ALTO) zijn eenvoudig te indexeren en doorzoekbaar te maken met zoektechnologie als ElasticSearch. En het leuke is, als je dit hebt, ben je ook klaar voor het andere deel van scans waar op termijn de inhoud via het HTR-proces van beschikbaar komt.
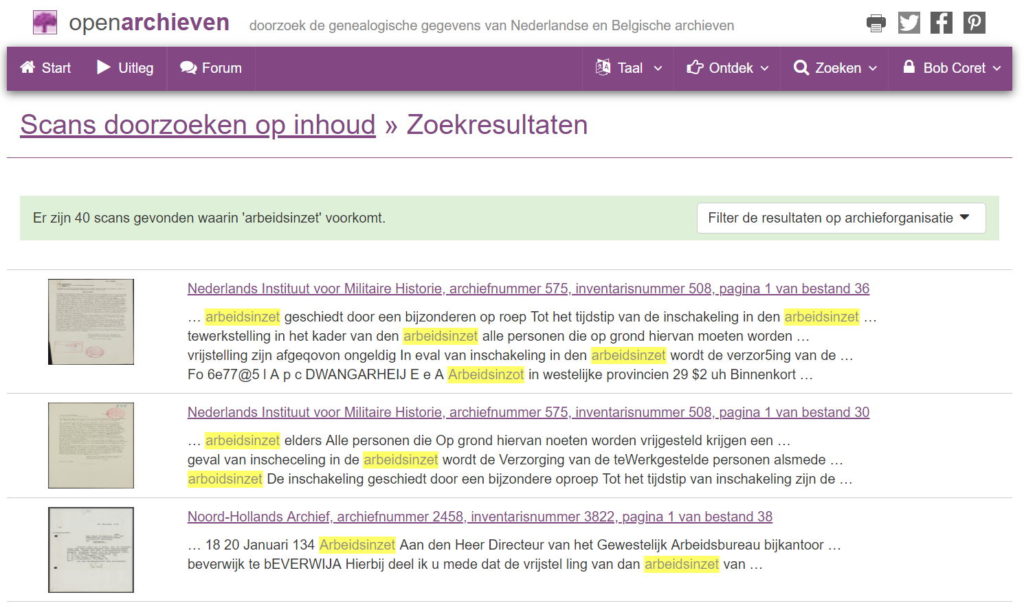
Voor archieforganisaties die een dergelijke “Delpher voor archiefstukken” nog niet voor zich zien, heb ik een Proof of concept gerealiseerd: Scans doorzoeken op inhoud. Deze zoekmachine op Open Archieven maakt een steekproef van bijna 16 duizend pagina’s (afkomstig van diverse archieforganisaties) doorzoekbaar. De gevonden pagina’s worden via een IIIF-viewer getoond, uiteraard met bronvermelding en zoekwoordmarkering.

Dag Rob,
Wat een mooie proef van je. Ik kan je melden dat het digitaal doorzoekbaar maken van de archieven sample mij al een hit heeft opgeleverd van een document waarvan ik noch het bestaan kon vermoeden, noch ooit naar gezocht heb.
821-1 Gemeentelijk inkwartieringsbureau voor de Duitsche weermacht ‘Quartieramt’ en Dienst inkwartiering herstel en afwikkeling (D.I.H.A.) > Inventaris > 1. Archief van het Quartieramt, 1940-1945 > 1.1. Stukken van algemene aard > 53 Staat van de gebouwen, in gebruik (geweest) bij de Duitse bezetter, met o.a. vermelding van de gebruiker (militair of civiel) en de gebruiksperiode, 1940-1945
Ongetwijfeld liggen er nog veel meer pareltjes op mij en anderen te wachten om gevonden te worden.
Michaël Boers
Prachtig om zo te kunnen zoeken en vinden. Maar: wat te doen met 1. schrijffouten, 2. oude spelling (dubbel e, of sch, bijvoorbeeld), 3. scanfouten (een n wordt weergegeven als m bijvoorbeeld, of een gedeelte van de tekst valt er buiten door schaduw of bolling van papier)?, 4. foto’s ook?. En: Nederlandstalige zoektermen zijn ook te vinden in andere talen (bijv.: Arbeitseinsatz, Evakuation, Konzentrationslager).
HTR is lastiger dan je denkt. Het programma moet “getraind worden”: mensen moeten een deel van de tekst transcriberen. Met die transcripties kan het programma de teksten “leren lezen”.
Ik heb kort geleden deelgenomen aan zo’n transcriptie-sessie. Daarin zijn plm. 100 van 1000 brieven van 1 persoon getranscribeerd, waarna de computer op de rest werd losgelaten. En ja, voor ieder handschrift moet dit opnieuw. Dus nog werk genoeg voor alle vrijwilligers.